这篇文章是关于如何在ECS实例上快速搭建Hadoop伪分布式环境的教程。主要步骤包括安装JDK,安装Hadoop,配置Hadoop,配置SSH免密登录,以及启动Hadoop。每个步骤都有详细的命令和操作说明,以及相关的参考链接。完成所有步骤后,可以通过访问特定的URL来验证Hadoop环境是否已成功搭建。
大多数教程都是从 http://s.iarno.cn/pegHbK 下载安装包,目前该网站已收费,所以另寻途径安装hadoop环境。
背景信息
Hadoop是一款由Apache基金会用Java语言开发的分布式开源软件框架,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的能力进行高速运算和存储。Hadoop的核心部件是HDFS(Hadoop Distributed File System)和MapReduce:
- HDFS:是一个分布式文件系统,可对应用程序数据进行分布式储存和读取。
- MapReduce:是一个分布式计算框架,MapReduce的核心思想是把计算任务分配给集群内的服务器执行。通过对计算任务的拆分(Map计算和Reduce计算),再根据任务调度器(JobTracker)对任务进行分布式计算。
更多信息,请参见Hadoop官网。
操作步骤
在ECS实例上快速搭建Hadoop伪分布式环境的操作步骤如下:
步骤一:安装JDK
远程连接已创建的ECS实例。
具体操作,请参见连接方式概述。
-
执行以下命令,下载JDK 1.8安装包。
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz -
执行以下命令,解压下载的JDK 1.8安装包。
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz -
执行以下命令,移动并重命名JDK安装包。
本示例中将JDK安装包重命名为
java8,您可以根据需要使用其他名称。mv java-se-8u41-ri/ /usr/java8 -
执行以下命令,配置Java环境变量。
如果您将JDK安装包重命名为其他名称,需将以下命令中的
java8替换为实际的名称。echo 'export JAVA_HOME=/usr/java8' >> /etc/profile echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile source /etc/profile -
执行以下命令,查看Java是否成功安装。
java -version如果返回以下信息,则表示Java已安装成功。
openjdk version "1.8.0_41" OpenJDK Runtime Environment (build 1.8.0_41-b04) OpenJDK 64-Bit Server VM (build 25.40-b25, mixed mode)
步骤二:安装Hadoop
-
执行以下命令,下载Hadoop安装包。
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz -
执行以下命令,解压Hadoop安装包至/opt/hadoop。
tar -zxvf hadoop-2.10.1.tar.gz -C /opt/ mv /opt/hadoop-2.10.1 /opt/hadoop -
执行以下命令,配置Hadoop环境变量。
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile source /etc/profile -
执行以下命令,修改配置文件yarn-env.sh和hadoop-env.sh。
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh -
执行以下命令,测试Hadoop是否安装成功。
hadoop version如果返回以下信息,则表示安装成功。
Hadoop 2.10.1 Subversion https://github.com/apache/hadoop -r 1827467c9a56f133025f28557bfc2c562d78e816 Compiled by centos on 2020-09-14T13:17Z Compiled with protoc 2.5.0 From source with checksum 3114edef868f1f3824e7d0f68be03650 This command was run using /opt/hadoop/share/hadoop/common/hadoop-common-2.10.1.jar
步骤三:配置Hadoop
修改Hadoop配置文件core-site.xml。
-
执行以下命令,进入编辑页面。
vim /opt/hadoop/etc/hadoop/core-site.xml -
输入
i,进入编辑模式。 -
在
<configuration></configuration>节点内,插入如下内容。<property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop/tmp</value> <!-- 自行修改 --> <description>location to store temporary files</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:8020</value> <!-- host+port自行修改 --> </property> -
按
Esc,退出编辑模式,并输入:wq保存并退出。
修改Hadoop配置文件hdfs-site.xml。
-
执行以下命令,进入编辑页面。
vim /opt/hadoop/etc/hadoop/hdfs-site.xml -
输入
i,进入编辑模式。 -
在
<configuration></configuration>节点内,插入如下内容。<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop/tmp/dfs/data</value> </property> -
按
Esc,退出编辑模式,并输入:wq后保存并退出。
步骤四:配置SSH免密登录
-
执行以下命令,创建公钥和私钥。
ssh-keygen -t rsa回显信息如下所示,表示创建公钥和私钥成功。
[root@iZbp1chrrv37a2kts7sydsZ ~]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:gjWO5mgARst+O5VUaTnGs+LxVhfmCJnQwKfEBTro2oQ root@iZbp1chrrv37a2kts7s**** The key's randomart image is: +---[RSA 2048]----+ | . o+Bo= | |o o .+.# o | |.= o..B = + . | |=. oO.o o o | |Eo..=o* S . | |.+.+o. + | |. +o. . | | . . | | | +----[SHA256]-----+ -
执行以下命令,将公钥添加到authorized_keys文件中。
cd .ssh cat id_rsa.pub >> authorized_keys
步骤五:启动Hadoop
-
执行以下命令,初始化
namenode。hadoop namenode -format -
依次执行以下命令,启动Hadoop。
start-dfs.sh在弹出的提示中,依次输入
yes。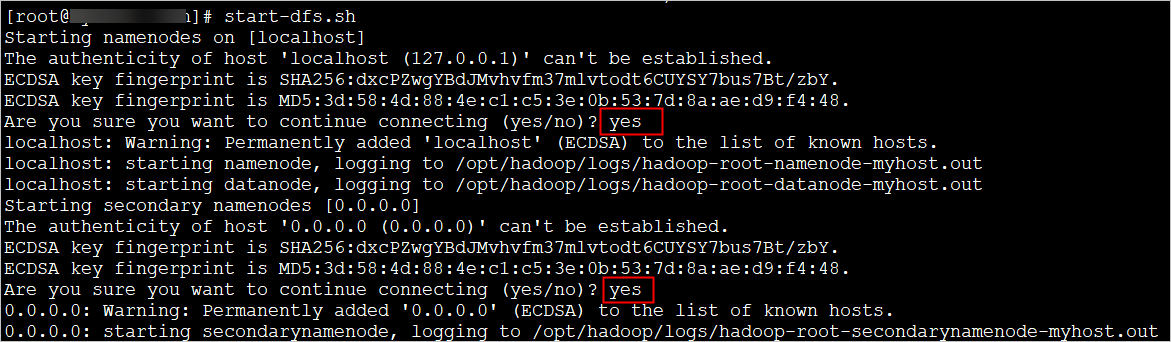
start-yarn.sh回显信息如下所示。
[root@iZbp1chrrv37a2kts7s**** .ssh]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /opt/hadoop/logs/yarn-root-resourcemanager-iZbp1chrrv37a2kts7sydsZ.out localhost: starting nodemanager, logging to /opt/hadoop/logs/yarn-root-nodemanager-iZbp1chrrv37a2kts7sydsZ.out -
执行以下命令,可查看成功启动的进程。
jps成功启动的进程如下所示。
[root@iZbp1chrrv37a2kts7s**** .ssh]# jps 11620 DataNode 11493 NameNode 11782 SecondaryNameNode 11942 ResourceManager 12344 Jps 12047 NodeManager -
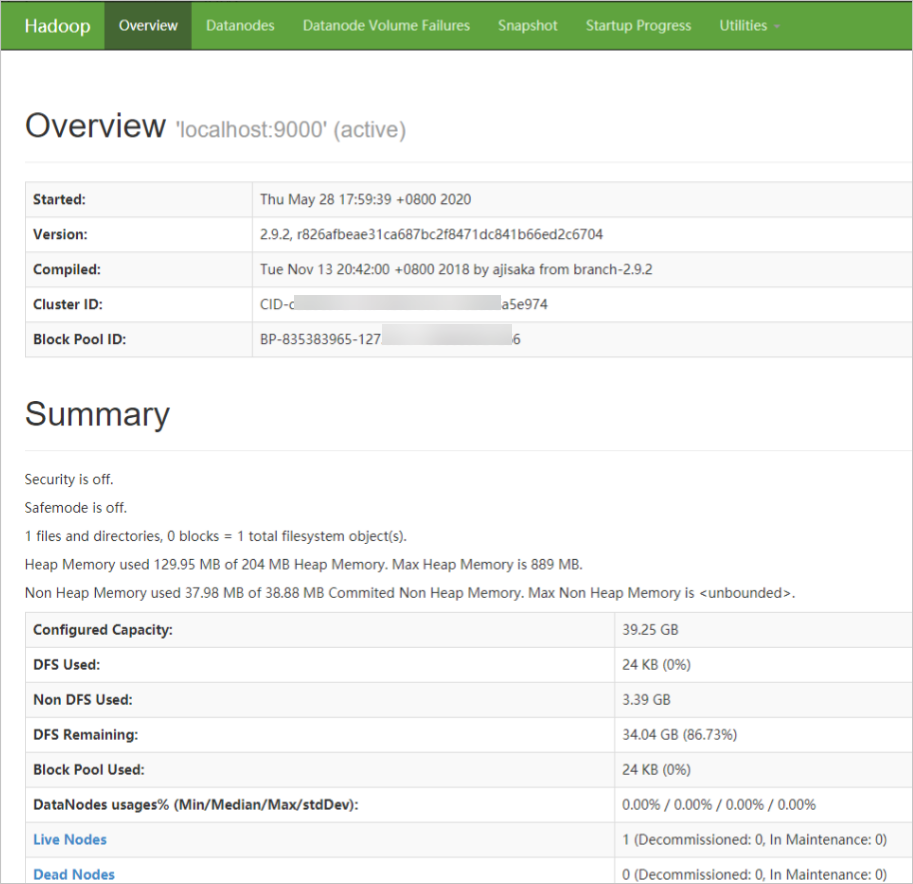
打开浏览器访问
http://<ECS公网IP>:8088和http://<ECS公网IP>:50070。显示如下界面,则表示Hadoop伪分布式环境已搭建完成。
注意 需确保在ECS实例所在安全组的入方向中放行Hadoop所需的8088和50070端口,否则无法访问。具体操作,请参见添加安全组规则。